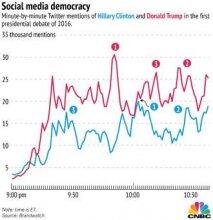
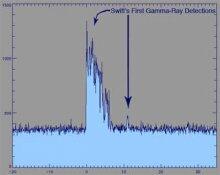
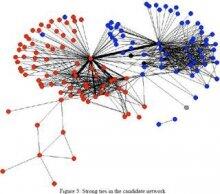
Politics is, at its core, a network phenomenon. Power - the central construct of political science - is intrinsically relational, where power exists between actors and among actors in a complex, differentiated fashion. India looms large for Nepal, not for Iceland. My boss is important to me, not you. More generally, we talk to people who affect what we think. Access and relationships among the powerful is indisputably important. One of the major subfields of political science is actually called international relations. And, as discussed below, there is a long standing interest in political science in networks, from the first years of the emergence of sociometrics. Perhaps the earliest effort in detecting clusters from relational data, one of the hottest areas in the study of networks currently, appeared in the American Political Science Review - in 1927 (Rice, 1927)! The first author on the first paper in the first issue of Social Networks was by one of the giants of the 20th Century political science, Ithiel de Sola Pool. This paper, circulating in unpublished form starting in the 1950s, was also the first to formulate the small world problem. One of the key drivers of the interest in networks the last 20 years has ben the vein of research on social capital - in part kicked off by research by a political scientist, Putnam et al. (1993), Putnam (2001). Given this history, it is therefore surprising that in the 20th century networks as a construct did not find a comfortable home within the discipline of political science, with a minimal presence in disciplinary journals. This has changed dramatically in the last decade, as part of a broader upsurge in interest in networks within the academy. One small illustration of this may be seen by the increase in the presence of networks at the annual meeting of American Political Science Association. A perusal of the program would have yielded few if any explicitly network related papers in any given year in the 1990s. In contrast, in the 2013 program, there are 23 network-themed panels, and over 100 papers explicitly evoking network concepts and data. This special issue thus represents an overdue reunion for the discipline and social network analysis. Our objective in this paper is to provide an overview of the trajectory of the research on political networks, and to place the contributions in this issue in that context. We begin with a short intellectual history of the long standing, if thin, history of network scholarship in the study of politics, maneuvering through the various, loosely coupled subfields of political science, and concluding with a discussion of what impact political science will have on the field of social networks as both move forward together.