
Manual annotations are a prerequisite for many applications of machine learning. However, weaknesses in the annotation process itself are easy to overlook. In particular, scholars often choose what information to give to annotators without examining these decisions empirically. For subjective tasks such as sentiment analysis, sarcasm, and stance detection, such choices can impact results. Here, for the task of political stance detection on Twitter, we show that providing too little context can result in noisy and uncertain annotations, whereas providing too strong a context may cause it to outweigh other signals. To characterize and reduce these biases, we develop ConStance, a general model for reasoning about annotations across information conditions. Given conflicting labels produced by multiple annotators seeing the same instances with different contexts, ConStance simultaneously estimates gold standard labels and also learns a classifier for new instances. We show that the classifier learned by ConStance outperforms a variety of baselines at predicting political stance, while the model’s interpretable parameters shed light on the effects of each context.
Publications by Type: Conference Paper
2017
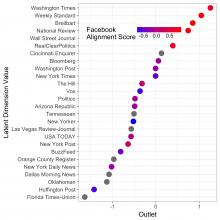
The present work proposes the use of social media as a tool for better understanding the relationship between a journalists’ social network and the content they produce. Specifically, we ask: what is the relationship between the ideological leaning of a journalist’s social network on Twitter and the news content he or she produces? Using a novel dataset linking over 500,000 news articles produced by 1,000 journalists at 25 different news outlets, we show a modest correlation between the ideologies of who a journalist follows on Twitter and the content he or she produces. This research can provide the basis for greater self-reflection among media members about how they source their stories and how their own practice may be colored by their online networks. For researchers, the findings furnish a novel and important step in better understanding the construction of media stories and the mechanics of how ideology can play a role in shaping public information.
Understanding the factors of network formation is a fundamental aspect in the study of social dynamics. Online activity provides us with abundance of data that allows us to reconstruct and study social networks. Statistical inference methods are often used to study network formation. Ideally, statistical inference allows the researcher to study the significance of specific factors to the network formation. One popular framework is known as Exponential Random Graph Models (ERGM) which provides principled and statistically sound interpretation of an observed network structure. Networks, however, are not always given set in stone. Often times, the network is "reconstructed" by applying some thresholds on the observed data/signals. We show that subtle changes in the thresholding have significant effects on the ERGM results, casting doubts on the interpretability of the model. In this work we present a case study in which different thresholding techniques yield radically different results that lead to contrastive interpretations. Consequently, we revisit the applicability of ERGM to threshold networks.

Over the past 12 years, nearly 20 U.S. States have adopted voter photo identification laws, which require voters to show a picture ID to vote. These laws have been challenged in numerous lawsuits, resulting in a variety of court decisions and, in several instances, revised legislation. Supporters argue that photo ID rules are necessary to safeguard the sanctity and legitimacy of the voting process by preventing people from impersonating other voters. They say that essentiall every U.S. citizen possesses an acceptable photo ID, or can relatively easily get one. Opponents argue that that’s not true; that laws requiring voters to show photo ID disenfranchise registered voters who don’t have the accepted forms of photo ID and can’t easily get one. Further, they say, these lallws confuse some registered voters, who therefore don’t bother to vote at all. Opponents also point out that there are almost no documented cases of voter impersonation fraud. Supporters counter that without a photo ID requirement, we have no idea how much fraud there might be.
2016

"Man is by nature a political animal," as asserted by Aristotle. This political nature manifests itself in the data we produce and the traces we leave online. In this tutorial, we address a number of fundamental issues regarding mining of political data: What types of data would be considered political? What can we learn from such data? Can we use the data for prediction of political changes, etc? How can these prediction tasks be done efficiently? Can we use online socio-political data in order to get a better understanding of our political systems and of recent political changes? What are the pitfalls and inherent shortcomings of using online data for political analysis? In recent years, with the abundance of data, these questions, among others, have gained importance, especially in light of the global political turmoil and the upcoming 2016 US presidential election. We introduce relevant political science theory, describe the challenges within the framework of computational social science and present state of the art approaches bridging social network analysis, graph mining, and natural language processing.
2014

Volunteer Science is an online platform enabling anyone to participate in social science research. The goal of Volunteer Science is to build a thriving community of research participants and social science researchers for Massively Open Online Social Experiments ("MOOSEs"). The architecture of Volunteer Science has been built to be open to researchers, transparent to participants, and to facilitate the levels of concurrency needed for large scale social experiments. Since then, 14 experiments and 12 survey-based interventions have been developed and deployed, with subjects largely being recruited through paid advertising, word of mouth, social media, research, and Mechanical Turk. We are currently replicating several forms of social research to validate the platform, working with new collaborators, and developing new experiments. Moving forward our priorities are continuing to grow our user base, developing quality control processes and collaborators, diversifying our funding models, and creating novel research.